



















|
|
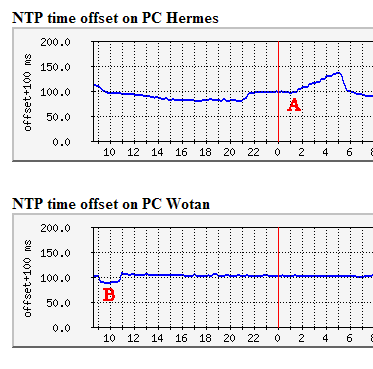
Using NTP and Windows PCs in a cable-modem environmentBackgroundI have always been interested in time, and have run NTP clients on my PCs for many years. I have run, and been quite happy with, Tardis, which has a graphical interface, provides facilities for automatically changing servers, and runs as a properly integrated NT service. However, a recent update of Tardis made me aware that a better method than stepping the time was available, changing the clock frequency slightly allowing the PC to drift into synchronisation rather than be stepped. Tardis allows this, but it also made me aware that there was free NTP server available for Windows PCs, based on the UNIX master. So I moved to the public Windows NTP server software, V4.1.71, and gave up the graphical control interface. In general, the results looked very good, and the accuracy was better than I had seen before. So good that I dusted off an old NTP Monitoring program, and gave it a shiny new graphical display, and dug a little bit into using MRTG to provide routine monitoring of my timekeeping. Imperfections with NTP on my PCsIt was with this monitoring that I started to notice some things happening that I didn't expect. For example, as you can see in the graphs below, sometimes a PC would start moving out of sync for no apparent reason. At A, PC Hermes suddenly starts to drift. What happened at 01:30 in the morning? Well, there was some intense local network activity backing up between PCs, so perhaps that had caused the apparent offset between the PC and its reference server on the Internet to increase, making the NTP service want to compensate?
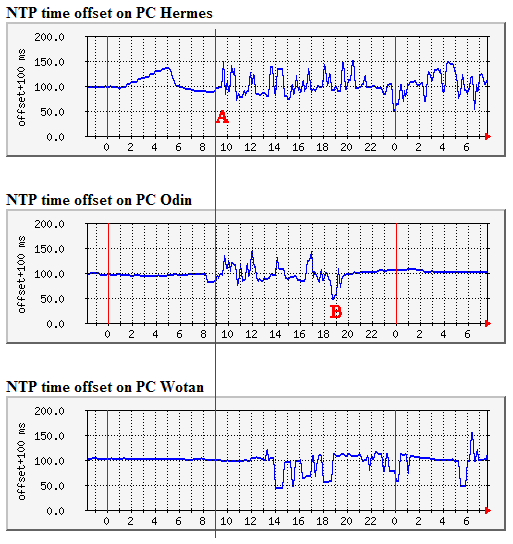
At B, PC Wotan decides to be 10 - 20ms off for nearly two hours. Why? I can't explain this one! Network ConfigurationPerhaps I should explain my networking configuration. I run a small network with a 4-port router. All PCs are connected at 100Mb/s, and the router is connected to the Internet through a cable-modem connection. This runs at 1Mb/s downstream, and 250Kb/s upstream. The network is simply monitored with MRTG and the performance data is on the Web. In trying to resolve where these timekeeping imperfections arose, it did occur to me that the asymmetry in my network connection might be causing NTP to measure the wrong offset between the PC and its remote reference. Asking on the newsgroups, resulted in the suggestion to install the huff-'n-puff filter, which is really designed for dial-up connections rather than a cable modem connection. However, I was quite happy to test it, and the results are shown below. Activating the Huff-'n-Puff filterI activated the huff-'n-puff filter on three out of the four PCs. As PC Bacchus had shown none of the drift of offset problems of the other PCs, there seemed no point in disturbing what appeared to be a satisfactorily working setup. However, the results were not what I expected. I activated the filter at about 09:00 (A below), and immediately two out of the three PCs exhibited some 50ms of randomness in their timekeeping. PC Wotan seemed to be OK until about 14:00, when it too started exhibiting random offsets. (All through this period, PC Bacchus remained stable). Because this filter did not seem to be working as expected, I switched if off on PC Odin at about 19:00 (B below), when stable behaviour resumed within a few minutes. The two remaining PCs continued to exhibit erratic behaviour.
I turned the huff-'n-puff filter off at 08:00 on the remaining PCs (just in case you look at the current data). Playing with ntp structure and maxpollI was still seeing wild swings on PC Odin, and a lot more variation than I liked on PC Hermes. Even now, I do not understand why NTP allowed PC Hermes to get so far out before correcting it. Don't get me wrong, so far out is only 1/20 second, still very good! However, PC Hermes seemed to be far worse than Bacchus or Wotan. Odin has its own problems - creating or viewing animations seemed to cause large steps in offset, possibly caused by lost interrupts? So what other parameters could I play with to help Hermes and Wotan? Starting with Hermes, just as a trial, I set the maximum polling interval, maxpoll, down a little, and the variations were reduced. Lowering maxpoll a little more, even less variation. However, conscious of being a "good" ntp citizen, I realised that I simply could not just poll all external servers at 64s intervals without running a serious risk of being thrown off them for abuse, so I looked again at how I was running NTP. I was syncing all four PCs to external sources, actually using a common ntp.cfg file. I didn't want to rely on just one local server being synced externally, in case it went down, but I would risk just two. So suppose that I synced my two "best" servers to external sources at the normal 1024s maxpoll, and synced my two "worst" servers internally at 64s intervals to my two "best" servers. Well the result was a dramatic improvement!
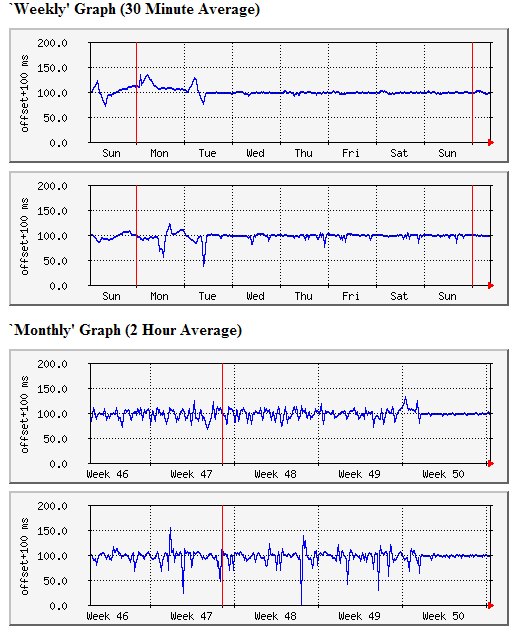
In the graphs above, you can see what happened at 10:00 on Tuesday of week 50. I changed the two servers shown to sync at 64s maxpoll to my two remaining Internet synced servers. Reducing maxpoll to 64s has made the servers react much more quickly to the clock disturbances that were experienced without, apparently, increased short-term noise. This change is particularly clear on the Monthly graph.
Would a 64s maxpoll be appropriate on the Internet? Well, apart from the fact that it is not good citizenship to do this, I think that for me the answer is no. My Internet use is bursty, and the cable-modem connection shared between four PCs. Thus if I sampled every minute, I would loose the averaging effect of the pll/fll filters built into ntp that smooth out such variations in the internet connection. It seems broadly reasonable - the Internet is "noisy" so use a narrow band filter, locally the network is much "cleaner" so use a wider bandwidth filter. Other issuesThe one remaining issue that I see is the effect of large file transfers from the Internet affecting the ntp sync on the Internet connected servers. The congestion caused by full-bandwidth file transfers results in much greater delay times, and therefore incorrect offset times. This produces a spike in the 24-hour graphs (5 minute sampling interval) which, I believe, actually represents a measurement error rather than a clock error (as ntp would not allow the clock to have such a spike with the 1024s maxpoll). Unless I can find a way to make my router give priority to ntp packets, the spikes may just be something that I have to live with! PC Configurations
Conclusions
The free NTP software does a first-class job, and has very knowledgeable support through the comp.protocols.time.ntp newsgroup. Many thanks to the people there who helped me. Current NTP graphs |
|
|